While there has been progress in reinforcement learning for tackling increasingly hard tasks, sparse-reward tasks with continuous actions still pose a significant challenge. Our paper presents a sample efficient technique for learning in sparse-reward temporally extended settings. It does not require any human demonstrations and can learn purely from sparse reward signals. Moreover, after learning low-level skills, it can learn to combine them to solve challenging new tasks without any requirement to interact with the environment.
We demonstrate our agent capabilities in a robotic manipulation environment. A robotic arm is facing 4 indexed coloured blocks on a table. The table contains also 2 colour zones: an orange and a blue one. We learn skills such as stacking blocks together or moving blocks to a zone depending of their colour.
Atomic programs
AlphaNPI-X combines a goal setter and a goal conditioned policy to learn low level skills that we call atomic programs. The atomic program stage can be interpreted as a reactive motor policy that learns in a continuous action space how to manipulate objects with the robotic arm. AlphaNPI-X learns 20 such atomic programs.
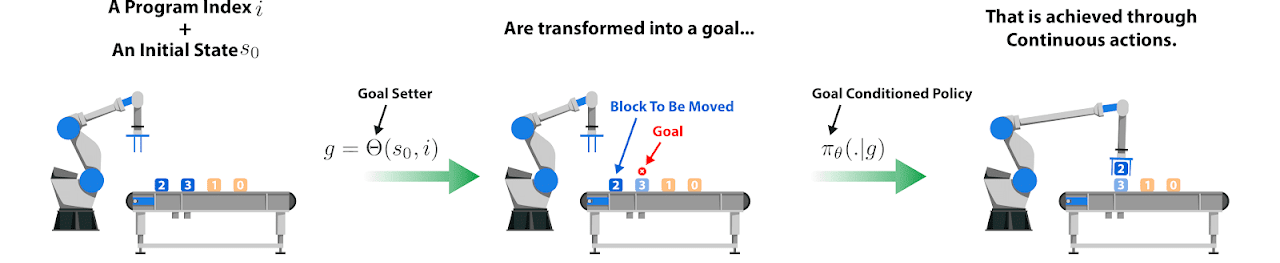
-

-
MOVE_TO_ZONE_0_BLUE
Move the block number 0 to the blue zone.
-

-
MOVE_TO_ZONE_0_ORANGE
Move the block number 0 to the orange zone.
-

-
STACK_1_2
Stack the block number 1 on top of the block number 2.
-

-
STACK_2_3
Stack the block number 2 on top of the block number 3.
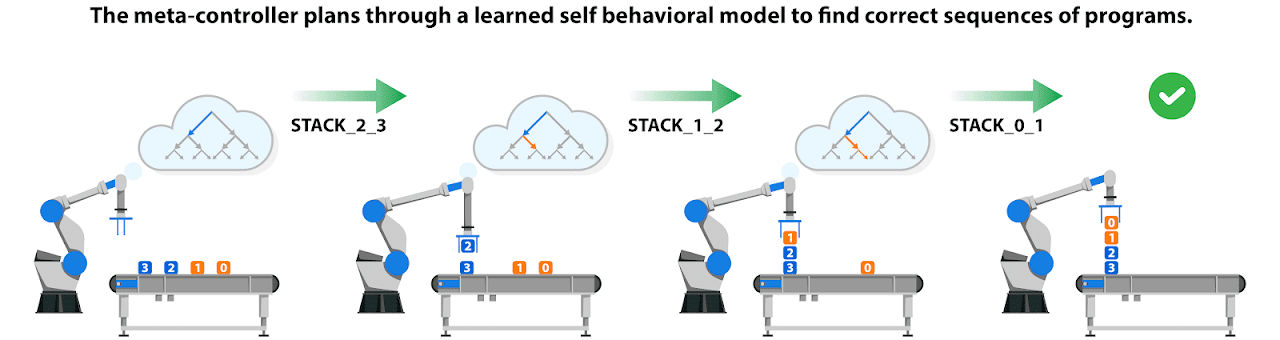
Meta-controller execution
Once the atomic programs are mastered, we learn a self behavioral model of these programs execution. This model takes an observation and a program index and predicts the state of the environment once this atomic program has been executed. This model enables AlphaNPI-X meta-controller to use recursive MCTS planning to execute higher level skills, dubbed non atomic programs, At the higher level, a meta controller plans through a behavioral model of the reactive policy to execute non atomic programs. It enables AlphaNPI-X to imagine likely future scenario at an abstract level without having to interact with the environment. AlphaNPI-X learns 7 non atomic programs.
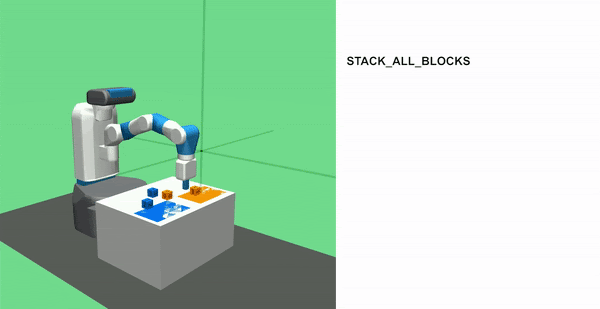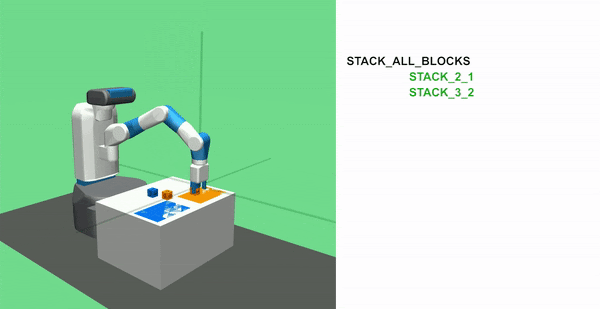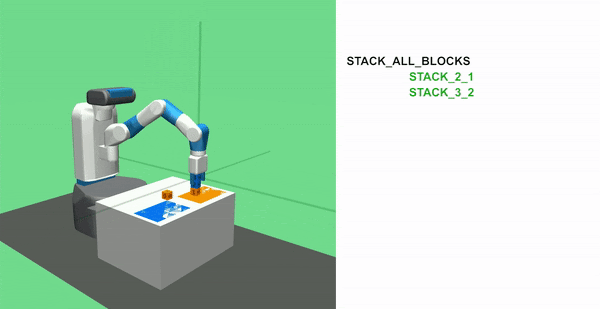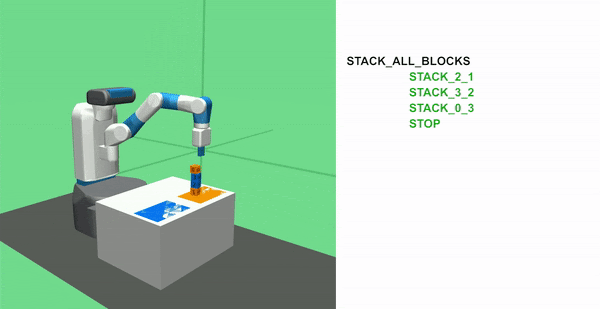
STACK ALL BLOCKS Task
In this task, the agent must stack 4 blocks together. It requires great precision as any incorrect move can invalidate the task by making the blocks fall at anytime.

STACK ALL TO ZONE ORANGE Task
In this task, the agent must stack the 2 orange blocks into the orange zone.

CLEAN TABLE Task
In this task, the agent must move the blue blocks to the blue zone (no stacking is expected) and similarly for the orange blocks.

CLEAN AND STACK Task
In this task, the agent must stack the blue blocks together in the blue zone and similarly for the orange blocks.